출간 : CVPRW 2021
저자 : Junlin Han, Mehrdad Shoeiby, Lars Petersson, Mohammad Ali Armin
주제 : Unsupervised Image Translation (GAN)
paper : 2104.07689.pdf (arxiv.org)
요약
unsupervised image translation에서 sota를 달성한 CUT를 기반으로 하여 만든 모델입니다.
CUT에선 하나의 Encoder를 사용했지만, 본 논문에선 2개의 Encoder를 사용하여 성능을 더 높였습니다.
추가로 CUT에서 발생하던 mode collapse에 대한 문제점도 효과적으로 처리했습니다.
(CUT review : 2022.01.16 - [GAN] - Contrastive Learning for Unpaired Image-to-Image Translation (CUT))
1. Introduction

CUT에서는 한 개의 encoder만을 이용하여 두 개의 도메인을 각각 embedding하였습니다. 그러나 이는 비효율적이라고 하네요. A domain과 B domain은 명백히 다른 종류의 이미지이니까요.
대표적인 예로 horse -> zebra를 학습한다면, horse를 embedding 하는 encoder와 zebra를 embedding 하는 encoder가 따로 있어야 한다는 내용입니다.
DCLGAN은 이처럼 dual learning을 하는 방식이라고 합니다.
전체적으로 CUT과 상당히 유사하지만 Encoder가 2개라는 점, 또 patch에서 RGB채널을 없앴다는 점을 대표적인 차이점으로 소개하네요.

2. Related works
생략
3. Method


먼저 generator로 G, F가 있습니다.
MLP layer는 Hx, Hy로 표현했네요. (CUT과 똑같습니다.)
아래는 Loss에 대한 설명입니다.

CUT에선 generator도 1개, discriminator도 1개였지만 DCLGAN은 전부 2개씩입니다.
따라서 Loss도 2개씩 계산해야합니다.
Adversarial loss는 뭐 설명이 필요없는 GAN의 필수 Loss입니다.

다음은 CUT의 핵심 아이디어인 Patch-NCE loss입니다.
당연히 mutual information을 maximize하는 것입니다.

CUT은 단순 내적을 했었다면, DCLGAN에서는 코사인 유사도를 사용합니다.
다른 계산 과정들은 CUT과 동일합니다.

당연히 Loss는 2개로 나눠서 계산합니다.

그 다음 Similarity loss입니다.
X, Y는 도메인을 의미하고, r과 f는 real, fake 입니다.
64-dims 를 가진 작은 네트워크입니다.

Similarity loss는 기본적으론 사용하지 않으나 특정 task에서만 mode collapse를 방지하기 위해서 사용합니다.
(아래에서 DCLGAN과 SimDCL로 나뉩니다.)

CUT과는 다르게 Identity loss를 추가했습니다.

최종적으로 DCLGAN의 Loss는 다음과 같습니다.
SimDCL은 여기에 sim loss가 추가된 형태입니다.
4. Experiments
생략
5. Results

CUT보다 좋은 성능으로 SOTA를 달성했습니다.

다만 맨 아랫줄의 이미지를 보시면 특이한 상황에 대해서는 물체와 배경을 잘 구분하지 못합니다.
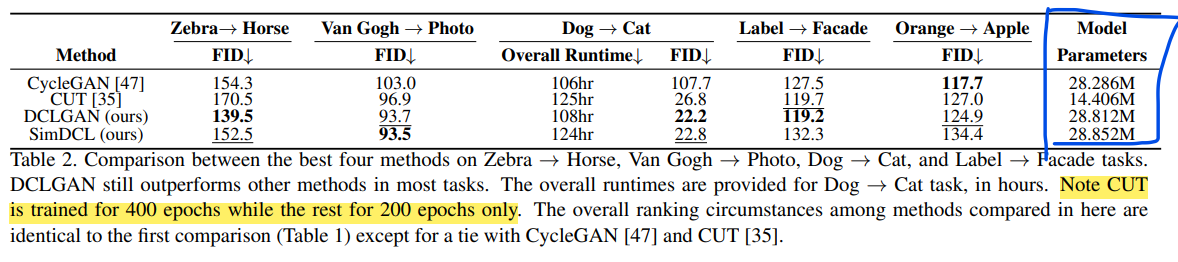
Table2는 random하게 뽑은 결과표라고 합니다.
CUT보다 parameter가 2배정도 많지만, 학습 횟수는 절반만 했다고 하네요.실제로 학습 시간도 조금 걸렸구요.
성능이 좋긴 하나 월등하다고 보긴 힘든 것 같네요.


그 다음 Sim loss에 관한 이야기입니다.
mode collapse를 해결하기 위해 sim loss를 사용했다고 합니다.
실제로 우측 이미지를 보시면 CUT, DCLGAN에 비해서 SimDCL은 mode collapse 현상이 해결된 것을 알 수 있습니다.
(추가로)

Appendix에 B.1에 mode collapse에 대한 내용이 조금 적혀 있습니다.
mode collapse는 diversities의 부족함 뿐만 아니라 이미지가 실제 이미지처럼 학습되지 않는다고 하는 경향이 있다고 하네요.
따라서 sim loss를 통해 실제 이미지와의 차이를 좁혀줍니다.
6. Ablation study

본문에선 5개의 Ablation study를 소개하는데요, 저는 한 가지에 대해서만 리뷰하겠습니다.
바로 FID 스코어가 아주 낮게 나온 2번에 대한 내용입니다.
2번은 (II) Effect of drawing external negatives 에 대한 내용입니다.

CUT에서도 이 내용에 대해서 나왔었습니다. 결론적으로 "internal negatives가 더 성능이 좋다"라는 얘기였죠.
DCLGAN에서 실험했을 때에는 FID score는 낮았지만, 실제 이미지 품질은 더 좋진 않았다고 합니다.
하지만 FID score가 낮았기 때문에 앞으로 새로운 sampling 방법이 충분히 나올 수 있다고 봅니다.

Appendix B.2에서도 이에 대하여 언급하네요.
마무리
CUT을 기반으로 만들어진 모델이기 때문에 CUT을 안다면 너무나도 쉽게 읽히는 논문인 것 같습니다.
이만 마치겠습니다.