저자 : Junho Kim, Minjae Kim, Hyeonwoo Kang, Kwanghee Lee
주제 : Unsupervised Image Translation (GAN)
GitHub - znxlwm/UGATIT-pytorch: Official PyTorch implementation of U-GAT-IT: Unsupervised Generative Attentional Networks with A
Official PyTorch implementation of U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation - GitHub - znxlwm/UGATIT-pytorch:...
github.com
- 요약
unsupervised image-to-image translation 에서 새로운 방법론을 제시하는 논문입니다. 새로운 attention module과 새로운 normalization function을 통합하여 2019년에 sota 성능을 보였습니다. 본 논문에서 제시하는 새로운 attention module은 이미지의 전체적인 변화와 지역적인 변화를 모두 조절할 수 있습니다. 또 새로운 normalization function은 AdaLIN (Adaptive Layer-Instance Normalization) 이란 이름으로 shape과 texture의 변화를 유연하게 조절합니다.
1. Introduction



(분홍색) abstract에서 말한대로 new attention module과 new normalization function 을 통합한 모델이라고 하네요.
(파란색) attention map을 기반으로 한 auxiliary classifier를 이용하여 source와 target 간의 중요한 지역과 중요하지 않은 지역을 구분한다고 합니다. generator에 있는 attention module이 두 이미지를 비교하여 fake image를 만들고, discriminator에 있는 attention module이 fake image와 real image를 비교하여 fine-tuning 하도록 도와준다고 합니다.
(녹색) AdaLIN 이라는 새로운 normalization function에 관한 설명입니다. Instance Normalization과 Layer Normalization의 비율을 Adaptive하게 조절하여 이미지의 shape과 texture를 조절한다고 합니다. Instance norm이 shape을 조절하고, Layer norm이 texture를 조절하겠네요.
2. UNSUPERVISED GENERATIVE ATTENTIONAL NETWORKS WITH ADAPTIVE LAYER-INSTANCE NORMALIZATION

attention module은 discriminator, generator 둘 다 들어가있습니다.
discriminator에 들어있는 attention은 target에 비슷한 부분을 찾도록 기능합니다.
generator에 들어있는 attention은 각 도메인을 구분하도록 기능합니다.
2.1 Generator

먼저 Generator입니다.
(ㄱ) 여느 모델들처럼 Encoder를 통해 작은 featuremap을 만듭니다.
(ㄴ) 그 다음 CAM의 기술을 사용합니다.
(ㄴ-1) pooling해서 나온 값을 fully connected layer를 통과시켜 logit값을 산출하고, 그 산출한 FC layer의 파라미터들을 encoder를 통과한 featuremap과 곱합니다.
(ㄴ-2) 이 과정을 GAP, GMP 각각 산출합니다.
(ㄷ) GAP, GMP로 나온 값을 concat한 후 CNN과 relu를 통과시켜 채널을 합칩니다.
(ㄹ) FC를 통해 gamma와 beta를 구합니다. (AdaLIN normalizer에 사용할 값들)
(ㅁ) Decoder를 통과시킵니다. (Decoder 안에 AdaLIN이 들어있습니다.)
def forward(self, input):
###(ㄱ)
x = self.DownBlock(input)
###(ㄴ)
gap = torch.nn.functional.adaptive_avg_pool2d(x, 1)
gap_logit = self.gap_fc(gap.view(x.shape[0], -1))
gap_weight = list(self.gap_fc.parameters())[0]
gap = x * gap_weight.unsqueeze(2).unsqueeze(3)
gmp = torch.nn.functional.adaptive_max_pool2d(x, 1)
gmp_logit = self.gmp_fc(gmp.view(x.shape[0], -1))
gmp_weight = list(self.gmp_fc.parameters())[0]
gmp = x * gmp_weight.unsqueeze(2).unsqueeze(3)
###(ㄷ)
cam_logit = torch.cat([gap_logit, gmp_logit], 1)
x = torch.cat([gap, gmp], 1)
x = self.relu(self.conv1x1(x))
heatmap = torch.sum(x, dim=1, keepdim=True)
###(ㄹ)
if self.light:
x_ = torch.nn.functional.adaptive_avg_pool2d(x, 1)
x_ = self.FC(x_.view(x_.shape[0], -1))
else:
x_ = self.FC(x.view(x.shape[0], -1))
gamma, beta = self.gamma(x_), self.beta(x_)
###(ㅁ)
for i in range(self.n_blocks):
x = getattr(self, 'UpBlock1_' + str(i+1))(x, gamma, beta)
out = self.UpBlock2(x)
return out, cam_logit, heatmap


Decoder에서 AdaLIN이라는 normalization 기법을 사용합니다.
rho 값에 따라서 Instance norm과 Layer norm의 비중을 조절합니다.
위에서 설명하듯 instance norm은 shape을 조절하고 layer norm은 texture를 조절하는 역할을 합니다.
content feature를 style feature로 전환하는 기법 중 대표적인 Whitening and Coloring Transform (WCT) 기법은 계산량이 상당히 많았다고 합니다. 이를 보완하기 위해 AdaIN이라는 기법이 나왔고, 또 AdaIN의 단점을 보완하기 위해, content information을 잘 파악할 수 있도록 Layer norm을 추가한 AdaLIN이라는 기술을 본 논문에서 제시합니다.
2.2 Discriminator

discriminator는 generator의 (ㄷ) 이후, CNN으로 logit을 산출합니다.
2.3 Loss
loss는 4가지를 사용합니다.
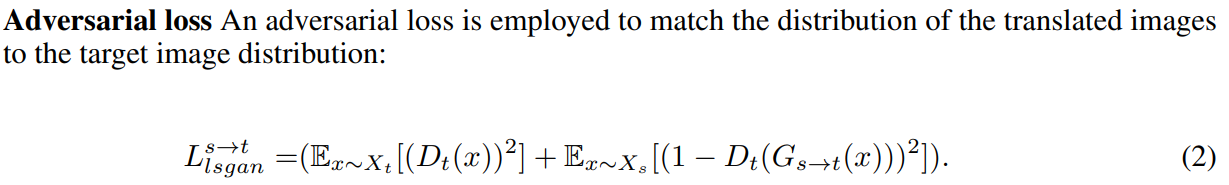



CAM loss에서 s->t은 fake_A2B는 1로, fake_A2A는 0으로 보내는 loss입니다.
이를 통해 두 도메인 간의 차이를 식별해낸다고 합니다.

discriminator의 학습 비중은 낮고, cam loss의 비중이 가장 크네요.
3. Experiments

CAM이 있고 없고가 굉장히 critical 하네요.


(b)의 이미지를 보면 attention feature map을 통해 특정 부위들을 잘 구분할 수 있다고 합니다.
또 U-Gat-It에선 총 4가지의 Discriminator를 사용합니다.(아래 코드 참조)
이를 통해 local과 global한 정보를 모두 구분할 수 있게 됩니다.
(GA = Global 정보 + A 이미지)
(LA = Local 정보 + A 이미지)
""" Define Generator, Discriminator """
self.genA2B = ResnetGenerator(input_nc=3, output_nc=3, ngf=self.ch, n_blocks=self.n_res, img_size=self.img_size, light=self.light).to(self.device)
self.genB2A = ResnetGenerator(input_nc=3, output_nc=3, ngf=self.ch, n_blocks=self.n_res, img_size=self.img_size, light=self.light).to(self.device)
self.disGA = Discriminator(input_nc=3, ndf=self.ch, n_layers=7).to(self.device)
self.disGB = Discriminator(input_nc=3, ndf=self.ch, n_layers=7).to(self.device)
self.disLA = Discriminator(input_nc=3, ndf=self.ch, n_layers=5).to(self.device)
self.disLB = Discriminator(input_nc=3, ndf=self.ch, n_layers=5).to(self.device)


그 다음은 AdaLIN에 대한 고찰입니다.
읽어보시면 될 것 같네요.
4. Conclusions

auxiliary classifier는 특정 지역들을 더 잘 분간하게 해줍니다.
AdaLIN은 content information을 더 잘 이해하게 해줍니다.
최종적으로 2019년에 unsupervised i2i translation task에서 SOTA를 만들어 냈었네요.
다음 논문 리뷰는 2020년에 나온 CUT.
다다음 논문 리뷰는 2021년에 나온 DCLGAN 예정입니다.