저자 : Andrew Brock, Soham De, Samuel L. Smith, Karen Simonyan
출간 : Deepmind
주제 : Image Classification
출처 : High-Performance Large-Scale Image Recognition Without Normalization (arxiv.org)
Github : deepmind-research/nfnets at master · deepmind/deepmind-research (github.com)
(pytorch framework : pytorch-image-models/nfnet.py at master · rwightman/pytorch-image-models (github.com))
- 요약

기존의 Batch Normalization(이하 BN)에는 단점들이 몇몇 있습니다. 본 논문은 BN을 없애고, Adaptive gradient clipping 기술을 통해 BN의 부재를 보완했습니다.
1. Introduction

먼저 BN의 단점을 소개하네요.
1. 높은 컴퓨팅 비용
2. 학습할 때와 추론할 때의 차이(학습할 때의 파라미터를 기반으로 추론을 하게 되죠)
3. mini-batch 학습의 독립성을 깨뜨린다.
3번이 가장 중요한 결함인데, 특히 분산 학습할 때 정보가 온전히 보존되지 못한다고 합니다.
(BN은 examples들을 기준으로 진행되는데, CPU 마다 examples들을 따로 할당하게 돼서 그런 것 같네요.)
그래서 contrastive learning이나 NLP에서도 BN 대신 다른 Noramlization 기법들을 사용합니다. 그 외에도 분산이 크거나, batch size가 작을 때도 안 좋다고 하네요.

BN의 단점을 극복하기 위해 여러 방법들이 나왔었으나 다 각자의 단점을 갖고 있었습니다. 그 중 Nomalizer-Free Resnet은 initialization에서 weight를 조절하고, Scaled Weight Standardization을 통해 regularization 한 기법입니다. 그러나 이 기법도 큰 배치 사이즈에서 불안정하고, Efficientnet만큼의 성능이 나오지 않았기 때문에 본 논문에선 Normalizer-Free Resnet 기법에 Adaptive Gradient Clipping(이하 AGC)를 추가하였다고 하네요.
2. Understanding Batch Normalization
(1) Batch normalization downscales the residual branch
- scale을 낮추어 학습이 안정화되면서 skip-connection을 붙일 수 있습니다.
(2) Batch normalization eliminates mean-shift
- ReLU 계열의 activation function들은 대칭(symmetric)이 아닙니다. 따라서 평균값이 0이 아닌 다른 값으로 이동하면서, 학습이 불안정해질 수 있으나 BN은 이를 방지합니다.
(3) Batch normalization has a regularizing effect
- training data의 noise들을 어느 정도 제거해줍니다.
(4) Batch normalization allows efficient large-batch training
- batch size를 크게할 수 있게 합니다. --> loss의 경사가 안정적이게 되면서 학습이 빨라집니다.
3. Towards Removing Batch Normalization
(1) Normalizer-Free ResNets


앞서 나온듯이 본 논문은 NF-ResNets를 사용한다고 합니다. residual block마다 \(h_{i+1} = h_{i} + \alpha f_{i}(h_{i}/\beta_{i})\) 방식으로 output이 나온다고 하네요.
(2) Scaled Weight Standardization Convolution

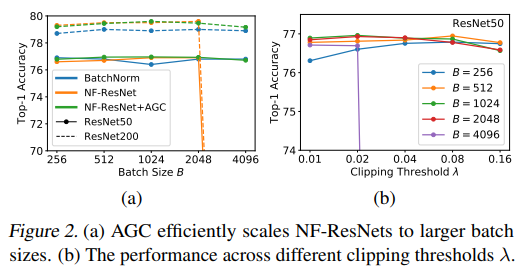
NF-ResNets에서 Convolution layer를 ScaledStdConv2d로 바꿉니다. 위에선 block 단위로 normalize 했다면, 이번에는 layer 단위로 normalize 하네요. activation에 감마를 추가로 곱하구요. 이를 통해 작은 batch size에선 좋은 성능을 보이지만, 4096 이상의 batch size에선 성능이 나빠진다고 합니다. 때문에 다음 과정이 또 추가됩니다.
4. Adaptive Gradient Clipping for Efficient Large-Batch Training
기존의 Gradient Clipping은 hyper-parameter인 람다를 조정하기가 어려웠습니다. 본 논문에선 큰 batch size에서도 학습이 잘 이뤄질 수 있도록 GC를 사용하지만, 위와 같은 단점을 극복하기 위해 AGC를 사용했다고 합니다.

norm 아래에 F는 Frobenius norm(2차원 matrix에서의 euclidean norm)을 뜻합니다. 그리고 layer 단위가 아니라, unit 단위로 clipping 한다고 합니다. 이를 통해 large batch size에서도, RandAugment와 같이 강한 Augmentation을 적용해도 안정적인 학습이 가능해지게 되었습니다.
4.1 AGC Ablations
생략
5. Normalizer-Free Architectures with Improved Accuracy and Training Speed


논문 발행 시점으로 SOTA 모델들은 EfficientNet 기반 모델들입니다. 이들은 test accuracy를 높이고, FLOP을 줄이는데 목적을 두었습니다. 그러나 그것이 학습 속도를 높이는 방향은 아닙니다.
NFNet은 학습 속도를 높이는데 중점을 둔 모델입니다.
- NFNet 모델 설명


(1) SE-ResNeXt-D를 base로 두고, GELU를 썼다고 합니다. 그리고 처음 stem에서 채널 output이 128로 나온다고 하네요.

(2) 기존의 방식들은 모델 앞단에 block을 작게 만들어놔서 general feature를 잘 학습하지 못했다고 합니다. NFNet에선 block size를 [1,2,6,3]을 기본으로 하여 early stage에서도 학습이 잘 이뤄지는 구조를 만들었습니다.

(3) 기존의 ResNet은 채널을 점점 증가시키는 패턴이었지만, NFNet은 3번째 스테이지와 4번째 스테이지의 채널이 같습니다. 이유는 뭐 당연히 더 정확하고 빠르니까요.


(4) 성능의 향상을 위해 bottleneck에서 3x3 conv를 추가했다고 합니다. 속도에 큰 영향이 없다고 하네요.

(5) EfficientNet과는 다르게 width pattern(채널 패턴)은 고정해놓고 모델을 scaling했다고 합니다.(depth, resolution만 scaling) 그리고 당연히 추론 이미지 사이즈보다 작은 이미지 사이즈로만 학습을 진행했습니다. 추가로 모델에 따라 dropout 비율도 다르게 학습했다고 합니다. (Table 1 참조)
5.1 Summary

생략
6. Experiments
생략
7. Conclusion

- 정확도 높아요
- 학습 속도 빨라요.
- AGC --> 큰 배치 사이즈 가능, 강한 augmentation 가능
- 큰 데이터셋에서 파인 튜닝하기엔 BN보다 좋다.
- 그러나 근래에 나온 EfficientNet V2 가 추론 속도나 정확도 면에서는 더 뛰어납니다.
Appendix는 나중에..