Semantic Image Synthesis with Spatially-Adaptive Normalization (SPADE, gauGAN)
저자 : Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
출간 : CVPR 2019
주제 : Supervised Image to Image (정확힌 semantic label map to photo-realistic image)
Framework : Pytorch
출처 : https://arxiv.org/abs/1903.07291
Github : NVlabs/SPADE: Semantic Image Synthesis with SPADE (github.com)
GitHub - NVlabs/SPADE: Semantic Image Synthesis with SPADE
Semantic Image Synthesis with SPADE. Contribute to NVlabs/SPADE development by creating an account on GitHub.
github.com
- 요약
semantic layout image를 photorealistic image로 변환시킬 때 일반적인 normalization layer는 semantic information을 날려버리게 됩니다. 본 논문에선 spatially-adaptive한 normalization layer를 통해 semantic information을 보존할 수 있는 방법을 제시합니다.

- 본문
1) Introduction
본 논문은 conditional image synthesis 기술 중에서도 'semantic segmentation mask' to a 'photorealistic image'에 특화된 기술입니다. 지금까지의 semantic image synthesis는 normalization layer가 semantic information을 "wash out" 하기 때문에 최적의 구조가 만들어지지 못했다고 합니다. 그래서 spatially-adaptive normalization을 제시한다고 하네요.
2) Related work
Deep Generative models - pass
Conditional image synthesis - pass
Unconditional normalization layers - Batch Norm, Instance Norm, Layer Norm, Group Norm, Weight Norm은 external data(norm layer의 parameters 외의 data)를 보지 않기 때문에 Unconditional normalization이라 정의한다고 합니다.
Conditional normalization layers - Conditional batch norm, Adaptive instance norm 과 같은 것들입니다. 이들은 external data를 참조합니다. 먼저 activation에 들어가기 전에 zero mean, unit deviation으로 normalized 한 뒤, external data에서 추출한 affine transformation parameters(gamma, beta)로 denormalized 합니다. (자세한 방법은 아래에서 다룹니다.) style transfer tasks의 affine parameter들은 global한 특징들을 대상으로 하지만, 본 논문에서 제시하는 Spatially-Adaptive norm은 semantic mask에 최적화된, 말 그대로 spatially-varying affine transformation입니다. 결과적으로 image style과 semantic information을 구분하는 generator를 만들게 됩니다.
3) Semantic Image Synthesis
Spatially-adaptive denormalization
network의 이름이 SPADE인 이유는 SPatially Adaptive DEnormalization 이기 때문이라네요. denormalize 방식은 간단합니다.
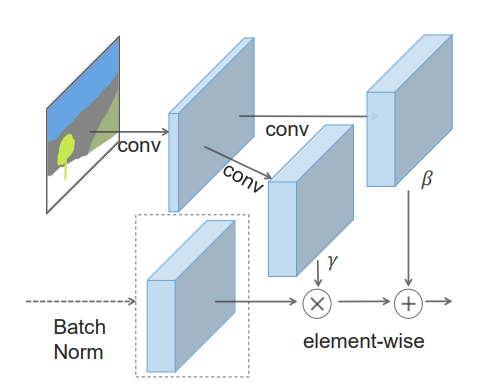

\(i\) : i-th layer
\(C^{i}\) : number of channels in the layer
\(H^{i}\) : height
\(W^{i}\) : width


semantic mask에 conv2d를 통과한 값을 modulation parameters(beta, gamma)로 사용합니다. 위의 그림처럼 beta, gamma는 Batch norm의 output과 shape이 같습니다. 이를 통해 Batch norm(혹은 Synchronized Batch norm)을 통과한 x와 element-wise 합니다. element-wise가 된다는 것은 각 feature map의 location 정보도 이용한다는 것입니다. 이는 batch norm과 극명한 차이점입니다. 또 modulation parameters는 segmantation mask를 1개만 받기 때문에 spatially-invariant한 특성을 가질 수 있습니다.(mini batch size = 1)
Spade Generator

보시다시피 블럭 중간중간마다 segmantic map이 계속 들어가기 때문에 generator 초기에 encoding하는 과정이 필요 없다고 합니다. (generator 첫단에 바로 downsample로 시작합니다.) 따라서 더 가벼운 network가 만들어진다고 하네요. 위의 그림을 보시면 pix2pixHD는 인코딩 후 디코딩이 들어가지만, SPADE는 처음에 downsample된 상태에서 점점 스케일을 upsample하며 최종 이미지를 만들어냅니다.
Loss function은 pix2pixHD에서 L2 loss만 L1-hinge로 바꾸고 동일하게 사용합니다. discriminator의 개수는 2개가 기본으로 설정되어있고, 각 discriminator는 5개의 conv를 갖고 있습니다. ( num_D = 2, num_intermediate_output=5)
adversarial hinge loss : \(\mathcal{L}_{adv} = \sum_{i=0}^{1} hinge(D_{i4}(G(x)))\) ( Discriminator(5개의 conv)를 통과한 마지막 output만 씁니다.)
feature matching loss : \(\mathcal{L}_{feat} = \sum_{i=0}^{1} \sum_{j=0}^{4} \lambda_{feat} \mid D_{ij}(G(x)), D_{ij}(x)\mid _{1}\)
perceptual loss (VGG loss) : \(\mathcal{L}_{per} = \sum_{i=0}^{4} \lambda_{i} \mid VGG_{i}(G(x)), VGG_{i}(x)\mid _{1} \)
(\(\lambda\) = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0])
$$ \mathcal{L}_{G} = \mathcal{L}_{adv} + \lambda_{feat} \mathcal{L}_{feat} + \lambda_{per} \mathcal{L}_{per} $$
$$ (\lambda_{adv} = \lambda_{feat} = 10) $$
$$ \mathcal{L}_{D} = \sum_{i=0}^{1} ( hinge(-D_{i4}(G(x)))) + hinge(D_{i4}(x)) ) $$
(논문에 나와있지 않아서 제가 코드를 직접 보고 쓴거라 틀린 부분이 있을 수 있습니다.)
Why does the SPADE work better?
semantic information을 보존하기 때문이라고 또 반복하네요. Instance norm과 비교를 하는데 읽어보면 될 것 같습니다.
Multi-modal synthesis
VAE를 앞에 붙여서 random vector를 받고 style transfer도 가능하다고 합니다. 다만 이 때엔 VAE도 학습되어야 하기 때문에 KLD loss도 추가 적용이 필요합니다.
4. Experiments

결과는 당시 sota였네요. 조금 지난 논문이기 때문에 생략하고 마치겠습니다.